
#29 - The Evolution of Databases: From Magnetic Tapes to Cloud Data Lakehouses
A brief history of data management technologies


For most data practitioners nowadays, it is easy to take for granted the abundance of database solutions, accessible for all types of companies from startup to enterprises. Storage is cheap, and computing is easily scalable. The job of a data engineer has changed from navigating an arbitrary system of points and links, to writing tedious MapReduce code, to configuring a highly abstracted workflow.
The world of data has been changing rapidly, and will continue to evolve at a magnificent speed. It can be scary at times. How can data practitioners keep themselves updated and stay relevant?
I’ve learnt a precious lesson recently, that history is a great teacher of any domain.By immersing ourselves into a long historical timeline of trials and errors, we may learn the keys to navigate the evolving future.
That lesson prompted me to dive into the evolution of databases. What I found from this dive is not just a timeline of inventions, but a holistic outlook onto what shapes the data management industry. I’d like to share them with you.
The 50s - 80s: From hierarchical to relational databases
The history of databases traces back to the 1950s when magnetic tapes were first used for data storage. This era saw payroll systems leveraging these tapes for data management. The oil and gas industry has used tape for years to capture, transport and store valuable data [1]. Still, tape limits users from randomly accessing data, due to its sequential writing and reading nature.
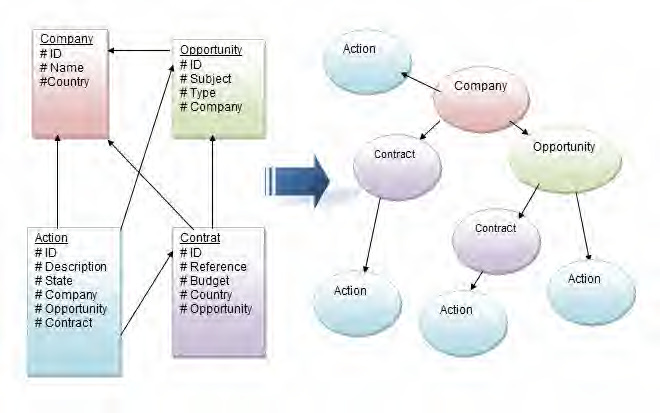
By the 1960s, the first breakthrough happened when the advent of hard disks enabled random data access. Still, there were still a lot of problems with latency. This era initially saw the first database system developed in a hierarchical nature. IBM’s hierarchical systems, such as IMS, introduced tree structures for data organisation, where the databases contain parents and child nodes, connected through pointers (See Figure 1). Accessing data remained cumbersome as these pointers were often arbitrarily set up, requiring the engineer to memorise these relationships in order to retrieve data. Famously coined by Charles W. Bachman - the creator of the first direct-access database management system- the programmer is the “navigator of a database” [2].
The 1970s heralded a revolutionary change in data modelling, with Ted Codd’s relational database model. This model eliminated the need for programmers to navigate complex pointer systems (See Figure 1). This shift towards data abstraction boosted productivity and led to the creation of SQL, a standardised language for querying relational databases. UC Berkeley’s Ingres and commercial RDBMS like Oracle began to emerge, setting the stage for Oracle’s dominance in the 1980s.
The 90s - mid 2000s: Distributed systems and networking change the game
”....to chase performance, you have to take advantage of the latest evolution in hardware, software and networking. So as hardware and networking is changing, database architecture is changing”. [3]
The last decade of the 20th century saw magnificent improvements in networking performance and storage capacity. This rise enabled fierce competition between Informix and Oracle, both requiring expensive hardware to scale databases. Databases at this time often cost millions of dollars to set up, consisting of large closets of hard drives and multi-processor computers from IBM.
The early 2000s brought a significant shift with the introduction of parallel shared-nothing architecture, which was estimated to be 300 times more efficient in terms of storage volume per dollar. Cost of databases could go down to ten, twenty thousand dollars. However, slow networking still posed a challenge for data reshuffling.
From 2005, the era of big data began with Hadoop, a distributed platform featuring a file system that allowed for MapReduce operations. In 2010, Facebook claimed that they had the largest Hadoop cluster in the world with 21 PB of storage. In June 2012, they announced the data had grown to 100 PB and later that year they announced that the data was growing by roughly half a PB per day. [4] However, Hadoops’ storage patterns and task management were not optimised for SQL operations. Open-source tools like Hive were developed to run SQL-like queries on top of Hadoop’s distributed file system. Still, Hadoop turned out to be more of a data lake, than a data warehouse.

Modern day: Post-big data era and the focus on data management
“Every five to seven years, database architecture shifts. And the reason database architecture shifts is because databases are always chasing performance, right?” [3]
In recent years, the emergence of cloud data lake houses has revolutionised data processing and storage. Leveraging the storage components of Hadoop but with new processing engines, new cloud-based solutions such as Snowflake and Databricks (built on Spark) overcome previous bottlenecks. Still, new challenges arise with the blessing of unlimited storage and fast networking: data swamp. This leads to an emerging mindset in data acquisition emphasising targeted data management, addressing regulatory concerns and optimising data handling from the outset. From 2010 till now, the modern datastack went through not one, but two Cambrian explosions [5], introducing endless innovations on various stages of the data management lifecycle: from ingestion, processing, to consumption.
Looking toward the future
From the magnetic tapes of the 1950s to the sophisticated cloud lake houses of today, the evolution of databases reflects continuous innovation in data management technologies. Many data management requirements that once used to be bottlenecks are now seamlessly tackled: from storage, retrieval, to processing.
Nowadays databases and architecture continue to see more challenges arise: governance, democratise data access, real-time streaming. But in the next 5 years, things may be much much different.
Footnote
TechTarget (Dec 2023) Magnetic tape. Link
Charles W. Bachman (Nov 1973) The programmer as navigator. Link
Data Engineering Podcast (Jan 2024) Modern customer data platform. Link
Hadoop Blog (May 2010) Facebook has the world’s largest Hadoop cluster. Link
Tristan Handy (May 2024) Future of the modern data stack. Link
Further Reading
Computer History Museum (2019 History of SQL. Link
Charles W. Bachman (Dec 2009) The Origin of the Integrated Data Store (IDS): The First Direct-Access DBMS. Link
Prof Ricardo Jimenez-Peris (Jul 2021) The case for shared nothing. Link
That’s it for this week! If you enjoy or get puzzled by the content, please leave a comment so we can continue the discussion. Throw in a like as or share as well if you know someone who may enjoy this newsletter. Thanks!