
#28 - The architectural choices for handling big data

Do you and your team handle big data? If so, what architecture choices should you follow? This week's issue is a refresher-read on the topic of big data architecture.
What is “true” big data?
Data is considered "big" when it exceeds the capacity of traditional data processing tools to handle, store, and analyse efficiently. This often involves datasets that are terabytes or petabytes in size, but the exact threshold can vary based on the specific use case and technological context.
In practice, most organisations do not deal with truly "big" data. Many enterprises have data warehouses smaller than a terabyte, and even large tech companies often manage data sizes in the range of terabytes rather than petabytes (MotherDuck).
What are the common architecture patterns for handling big data?
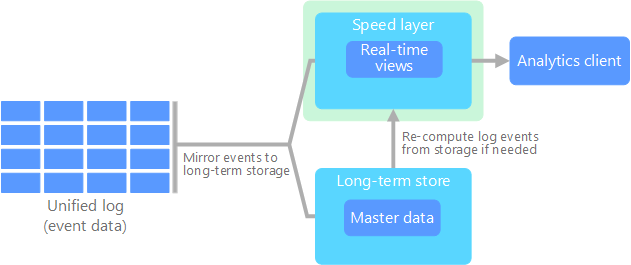
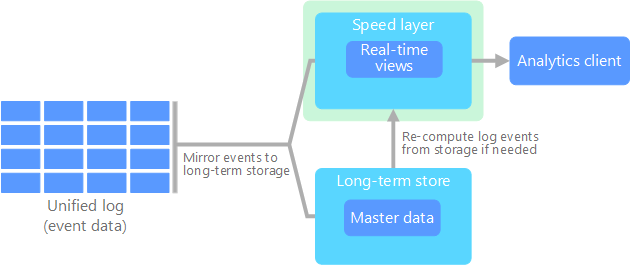
Lambda Architecture: This pattern involves two data processing paths: a batch layer (cold path) for high accuracy and a speed layer (hot path) for low latency. It combines real-time and batch processing to provide timely and accurate data insights.

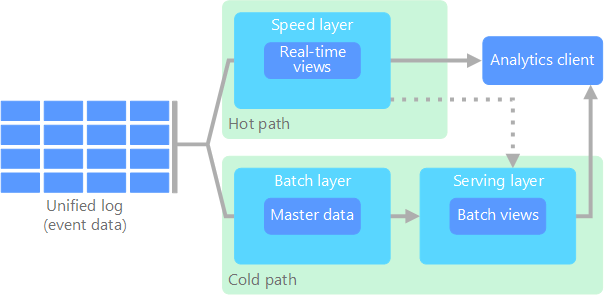
Lambda architecture. Source: Microsoft Kappa Architecture: An alternative to Lambda, Kappa architecture simplifies the process by using a single stream processing path for all data, eliminating the need for separate batch and speed layers. It focuses on real-time data processing and is suitable for scenarios where reprocessing of data is required.
Kappa architecture. Source: Microsoft
What are the differences between Lambda and Kappa architectures?
Lambda Architecture:
Use Cases: Ideal for applications requiring both real-time and historical data processing, such as fraud detection, recommendation systems, and analytics platforms.
Advantages: It ensures low-latency access to real-time data while maintaining the accuracy and completeness of batch-processed data.
Companies that have Lambda architecture: Netflix
Kappa Architecture:
Use Cases: Ideal for scenarios requiring real-time insights and low latency, such as tracking user engagement during live events or monitoring real-time metrics.
Challenges: It is less suitable for applications needing extensive historical data analysis. Despite its streamlined approach, Kappa Architecture can be complex and expensive to implement. Streaming systems can scale to large data volumes but are often harder to execute and manage compared to traditional batch processing systems.
Companies that have Kappa architecture: X

How to choose between Lambda and Kappa architecture?
Consider the need for historical data analysis.
Factor in the business context and enterprise architecture when estimating cost of maintenance.
Make reversible architecture choices: Kappa is just a variation of Lambda, design an experiment to benchmark the 2 architectures before choosing to stick with one.
Further reading materials:
Easy to understand articles comparing Lambda and Kappa architecture:
Real-life example:
Why should you even care? Perhaps not, as big data is only relevant for 1% of the companies - check out this thought-provoking piece: https://motherduck.com/blog/big-data-is-dead/
Getting intrigued and wanting to go all the way to the deep-end, this comprehensive list contains 100 open source big data architecture papers: https://www.linkedin.com/pulse/100-open-source-big-data-architecture-papers-anil-madan/
That’s it for this week! If you enjoy or get puzzled by the content, please leave a comment so we can continue the discussion. Throw in a like as or share as well if you know someone who may enjoy this newsletter. Thanks!